今天來試著抓文章的內文吧!這邊就用昨天的文章來作為爬取目標 ,順便偷人氣。
直接在內文中點選「右鍵 > 檢查」打開開發人員工具,可以直接定位到內文的元素 div.markdown__style,雖然上兩層還有 div.qa-markdown 和 div.markdown,但其中都只有一個子元素,所以直接定位到 div.markdown__style 就可以了。
import requests
from bs4 import BeautifulSoup
html_doc = requests.get('https://ithelp.ithome.com.tw/articles/10220022').text
soup = BeautifulSoup(html_doc, 'lxml')
# 先找到文章區塊
content = soup.find('div', class_='markdown__style')
print(content.text)
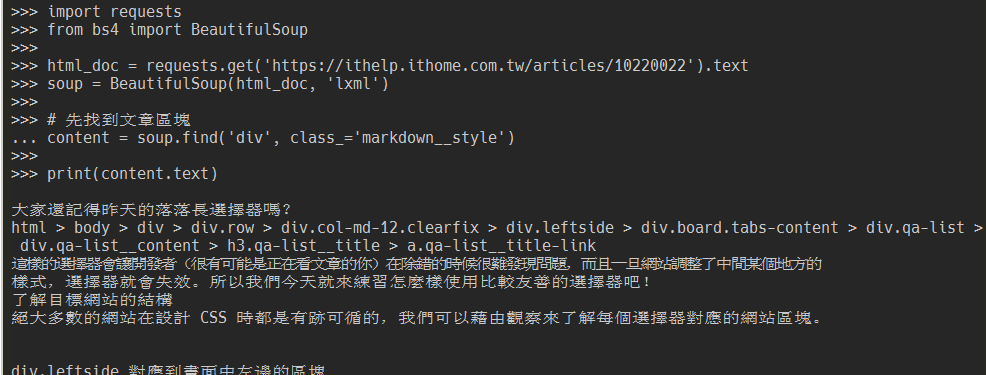
使用 content.text 取到的是 div.markdown__style 標籤下所有文字節點的內容,官方建議使用 get_text() 方法來取文字內容,可以顯示一些特殊字元(例如 \n)。
如果蒐集的資料是為了分析使用,一般不會把 \n 或 \r 這類的空白字元存起來,可以額外傳入參數把空白字元過濾掉。
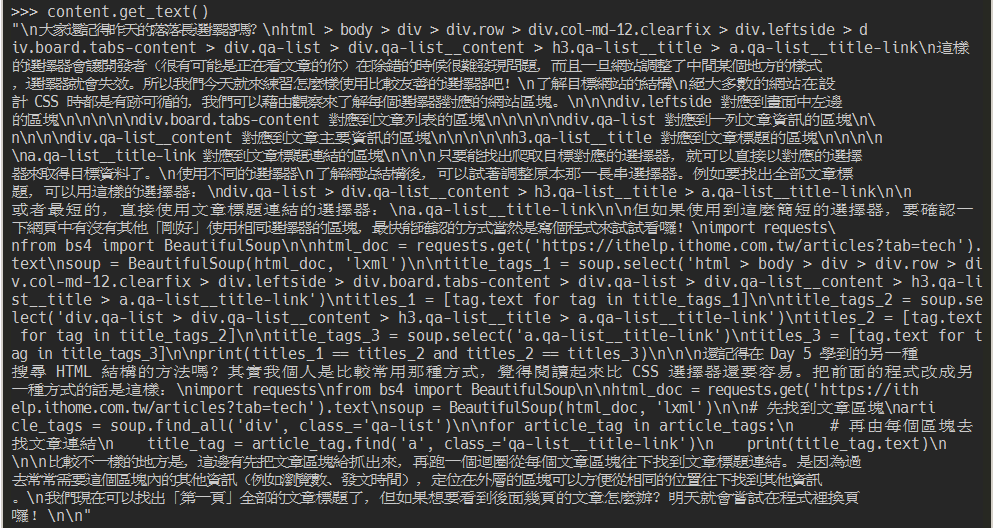
content.get_text(strip=True)
如果要對每個文字節點做額外處理,可以用 stripped_strings 這個屬性取得 generator。
[text for text in content.stripped_strings]
如果要取得含 HTML 標籤的結果,可以用 .decode_contents()。
content.decode_contents()
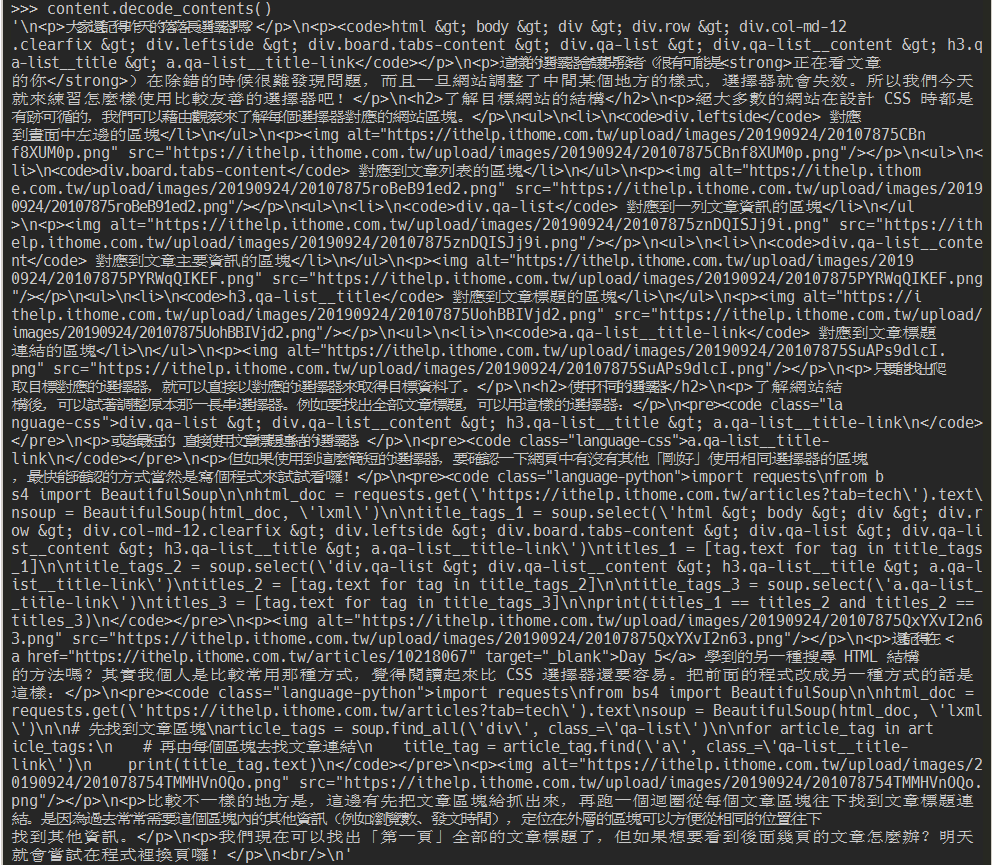
今天的內容比較簡單,因為 iT 邦幫忙的 HTML 結構相對不複雜,明天再來抓文章其他資訊吧~


 iThome鐵人賽
iThome鐵人賽